今天,测试反馈,一个组合场景,用压测平台测试的结果和机器直接执行压测的响应时间结果有一定出入
平台已更新到Github:
- 后端服务:https://github.com/100ZZ/mysterious
- 前端服务:https://github.com/100ZZ/mysterious-web
- 压测引擎:https://github.com/100ZZ/mysterious-jmeter
下面是平台压测的结果,原生JMeter的聚合报告报告详细数据如下

另外下面这个就是测试自己的一台服务器上,直接跑JMeter工具得到的结果

初略看了一下,考虑到下面信息
1、服务性能瓶颈 2、压力机配置差异 3、压测流程的差异
看了下被压测服务,无任何异常和报错,肯定还没有达到服务的性能瓶颈
接着看下压力机配置,测试同学用的是一台8C16G的虚拟机,而压测平台目前启用的是分布式中的一个4C8G的slave节点作为压力机,简单区分一下,资源如下

因此,就压力机来看,猜想会不会是4C8G压不上去,但就两次结果的响应时间对比来看,应该不会是这个原因
为了排除压力机自身资源的原因,将8C16G上的压测工具和脚本直接copy到禁用的slave节点B上,来直接进行一下压测,结果也很轻松地达到1900TPS,这里需要说明的是,SlaveA和SlaveB是完全一致的,并且所有的机器都在同一个局域网下,如此看来压力机配置应该也不是问题
接下来就只有分析一下两种压测方法,具体流程的差异了
8C16G直接压力机进行压测,这个没什么好说的;但压测平台就复杂了,有主从节点的交互,有压力机和压测服务之间的交互,但是仔细想一下,压测请求这个方向,应该是没有差异的,都是从压力机到达压测服务,可是响应这个方向,却有点没捋清楚,大概有这么几个疑问
1、响应时间的截止时间是到哪个节点 2、响应时间的截止时间戳是什么 3、回传的到底是什么数据
Google搜的东西都不是太清晰,基本都是如何分布式压测的流程,毫无营养,JMeter的源码是看不下去
基于这几个疑问,还想着直接抓包一次到位,在压测过程中,master节点,tcpdump抓一段时间的tcp报文,发现大量的数据传输都来自slave节点,而不是被压测服务的节点
简单用tshark聚合解析一下抓下来的pcap包,大致流程就是,slave节点起一条tcp连接,然后将数据都发给master节点

紧接着通过wireshark打开报文,想看看具体payload信息,甚至想看看更直接的耗时信息,没有能查出
但是起码知道了slave节点收到了响应数据之后,再回传给master节点,进而才会写jtl文件
先来看看jtl文件,因为里面记录了每条请求的数据,响应时间应该也是从这里面平均的
timeStamp,elapsed,label,responseCode,responseMessage,threadName,dataType,success,failureMessage,bytes,sentBytes,grpThreads,allThreads,URL,Latency,IdleTime,Connect
google可以找到这段解释
- Latency time = 接收到响应的第一个字节的时间点 - 请求开始发送的时间点 from just before sending the request to just after the first response has been received -- Apache JMeter Glossary - 响应时间(JMeter术语中的Elapsed time) = 接收完所有响应内容的时间点 - 请求开始发送的时间点 from just before sending the request to just after the last response has been received -- Apache JMeter Glossary
这么看来,elapsed应该就是响应时间了,做一个简单的校验,写一个python脚本计算下平均值,以1900TPS结果为例
#!/usr/bin/env python
import sys
my_file = sys.argv[1]
sum = 0
num = 0
with open(my_file) as f:
for line in f:
rtt = line.split(",")[1]
sum += int(rtt)
num += 1
print sum * 1.0 / num
以前两个API请求为例
lihui@2020 $ python time.py first.jtl 24.5626683929 lihui@2020 $ python time.py second.jtl 9.1986353298
小数点后两位数四舍五入,24.56和9.20,和一开始报告结果里的平均响应时间一致
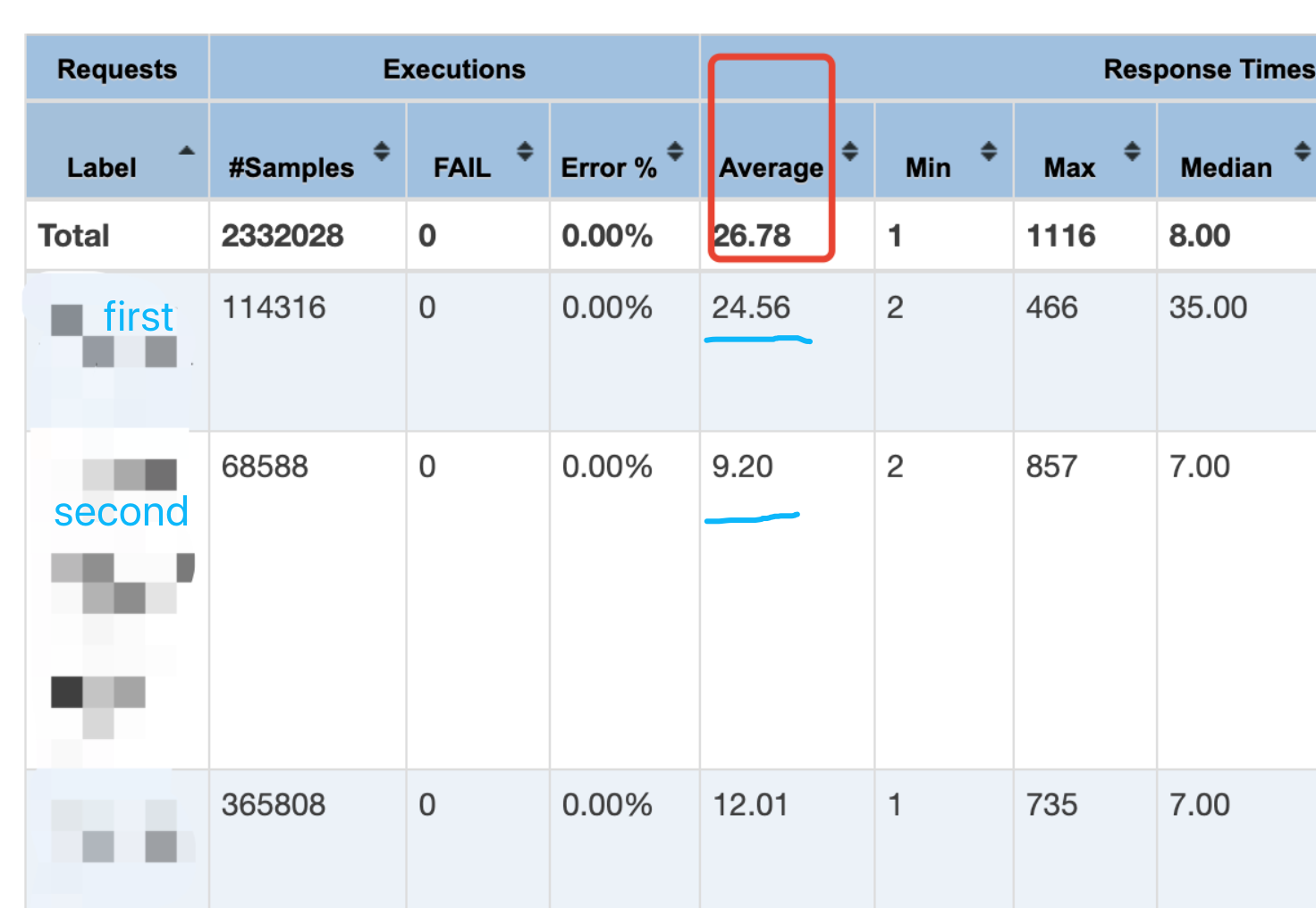
这么看来,jtl文件里elapsed = 接收完所有响应内容的时间点 – 请求开始发送的时间点对的上了,但是现在的问题是,接收完所有响应内容的时间点,对于分布式压测,到底是slave节点收到了响应内容的时间点,还是回传到master节点收到了响应内容的时间点;假如是slave节点收到的时间点,再将结果传到master写入jtl文件,就和单节点压测应该不会有损耗,假如是回传到master节点,作为截止的时间点,就会多了一段交互的时间
具体可参考下图

单节点压测,截止时间是:请求时间+X
分布式压测,截止时间是:请求时间+X+Y
而这个Y就是多出来的一段响应时间的开销,当然虽然看起来好像有可能,但目前都是自己的猜测
接下来为了证实这个观点,直接禁用掉A,也就是所有Slave节点都禁用,只用Master节点进行压测,压测平台触发,同时压测平台也是部署在这个节点上的,为了担心内存不够,扩了4G,变成了2C8G,应该不影响,因为资源应该不是瓶颈,压测的结果是能够达到1900TPS的
由此可见,不用分布式压测,压测平台直接触发Master单节点压测,和另外两种单节点压测结果一致,这么看来,应该真的是分布式多了网络开销导致
而对于这种差异影响,我这里的分析结果就是:
1、如果压测响应时间比较小,那么多的这段网络开销就比较明显,比如X0毫秒级别的,对于TPS影响就大了 2、如果压测响应时间比较大,X0毫秒级别只能当零头的,TPS影响就稍小了
测试了这么这些,总要有些收获和改进;这里我将压测平台master节点扩容,正常压测就直接单节点压测,不再进行分布式压测了,本来做一个节点管理,是为了担心压力机成为瓶颈,但不能弄巧成拙
最后分析了这么多,我也都是根据猜测来反证,并不能让人100%信服,比如有人提到了也可能IO读写问题,除非看JMeter源码,分布式压测的部分,响应时间的计算,截止时间到底是以什么时候为准,再结合上面的测试流程,应该就能得到真正的原因,自勉
