Kubernetes中有三种网络和三种IP。
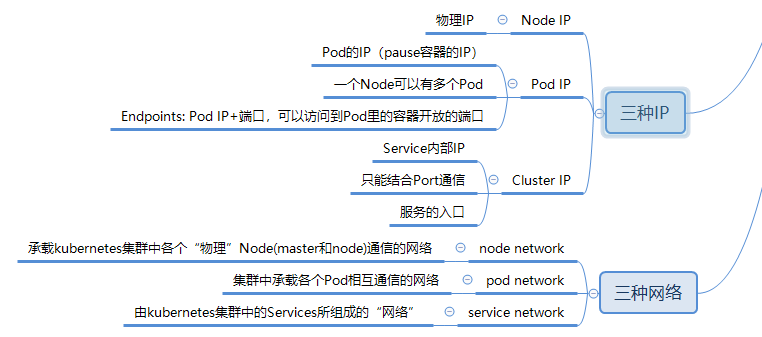
为了便于理解,我把Node IP比作tcp/ip网络结构中的第二层地址,mac地址。通过它去寻找节点的物理IP地址,而这个地址通常通常对Kubernetes里的Pod来说是透明的,不用知道其他Pod的Node IP,通过Pod IP就能访问到。所以Pod IP被我看做是网络结构中的三层IP地址。而Cluster IP更像是一个域名,不用知道背后到底有哪些Pod,他们又分布在哪里。当然,这只是一个不太恰当的比喻,但是我觉得背后的设计逻辑还是有点相通的地方。那,这三层的网络结构又是怎么搭建起来的呢,这就是我想在这里总结的内容。
一 docker网络实现
用过docker基本都知道,启动docker engine后,主机的网络设备里会有一个docker0的网关,而容器默认情况下会被分配在一个以docker0为网关的虚拟子网中。
root@VM-66-197-ubuntu:/home/ubuntu# ifconfig
...
docker0 Link encap:Ethernet HWaddr 02:42:ec:43:56:b2
inet addr:172.17.0.1 Bcast:0.0.0.0 Mask:255.255.0.0
...
root@VM-66-197-ubuntu:/home/ubuntu# docker inspect nginx
···
"IPAddress": "172.17.0.2",
···为了实现上述功能,docker主要用到了linux的Bridge、Network Namespace、VETH。
- Bridge相当于是一个虚拟网桥,工作在第二层网络。也可以为它配置IP,工作在三层网络。docker0网关就是通过Bridge实现的。
- Network Namespace是网络命名空间,通过Network Namespace可以建立一些完全隔离的网络栈。比如通过docker network create xxx就是在建立一个Network Namespace。
- VETH是虚拟网卡的接口对,可以把两端分别接在两个不同的Network Namespace中,实现两个原本隔离的Network Namespace的通信。
所以总结起来就是:Network Namespace做了容器和宿主机的网络隔离,Bridge分别在容器和宿主机建立一个网关,然后再用VETH将容器和宿主机两个网络空间连接起来。
1.1 CNM
基于上面的网络实现,docker的容器网络管理项目libnetwork提出了CNM(container network model)。
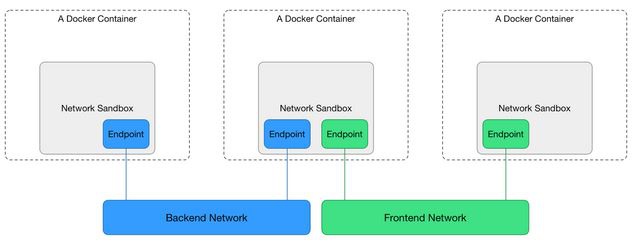
Sandbox:每个沙盒包含一个容器网络栈(network stack)的配置,配置包括:容器的网口、路由表和DNS设置等。Endpoint:通过Endpoint,沙盒可以被加入到一个Network里。Network:一组能相互直接通信的Endpoints。
Sandbox对应于Network Namespace, Endpoint对应于VETH, Network对应于Bridge。更多docker的网络实现可以参考:https://tonybai.com/2017/01/17/understanding-flannel-network-for-kubernetes/.
二 Pod Network
Kubernetes的一个Pod中包含有多个容器,这些容器共享一个Network Namespace,更具体的说,是共享一个Network Namespace中的一个IP。创建Pod时,首先会生成一个pause容器,然后其他容器会共享pause容器的网络。
root@kube-2:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d2dbb9e288e2 mirrorgooglecontainers/pause-amd64:3.0 "/pause" 3 weeks ago Up 3 weeks k8s_POD_frontend-647d9fdddf-n4x9w_default_9f275ea8-4853-11e8-8c42-fa163e4a07e5_0
cf1bfff28238 nginx "nginx -g 'daemon of…" 3 weeks ago Up 3 weeks k8s_nginx-demo_frontend-647d9fdddf-n4x9w_default_9f275ea8-4853-11e8-8c42-fa163e4a07e5_0
root@kube-2:~# docker inspect cf1bf
...
"NetworkMode": "container:d2dbb9e288e26231759e28e8d4816862c6c57d4d2822a259bee7fcc9a2fd0b20",
...可以看出,在这个Pod中,nginx容器通过”NetworkMode”: “container:d2db…”与pause容器共享了网络。这时候,相同容器之间的访问只需要用localhost+端口的形式,就像他们是部署在同一台物理机的不同进程一样,可以使用本地IPC进行通信。然而pause的ip又是从哪里分配到的?如果还是用一个以docker0为网关的内网ip就会出现问题了。
- docker默认的网络是为同一台宿主机的docker容器通信设计的,Kubernetes的Pod需要跨主机与其他Pod通信,所以需要设计一套让不同Node的Pod实现透明通信(without NAT)的机制。
- docker0的默认ip是172.17.0.1,docker启动的容器也默认被分配在172.17.0.1/16的网段里。跨主机的Pod通信要保证Pod的ip不能相同,所以还需要设计一套为Pod统一分配IP的机制。
以上两点,就是Kubernetes在Pod network这一层需要解决的问题。幸运的是有很多的网络工具已经实现了上述功能,所以Kubernetes选择了与这些工具结合。官方文档上可以看看有哪些网络插件可以使用:https://kubernetes.io/docs/concepts/cluster-administration/networking/#how-to-achieve-this
2.1 flannel网络插件
我在部署Kubernetes的时候,使用的是flannel,所以就根据flannel来说一下。在第二篇中说到过,etcd在Node中充当网络插件的网络状态同步组件。而flannel的功能实现就依赖于etcd。
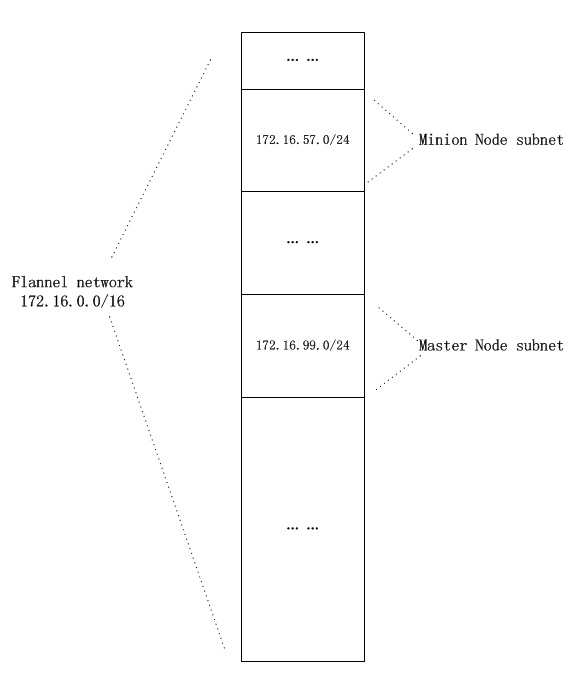
- 首先在启动Kubernetes Controller Manager时,需要指定集群的pod ip范围:–cluster-cidr=172.16.0.0/16,并开启为Node分配ip选项:–allocate-node-cidrs=true(参考kubeasz的配置)。Controller Manager会把为每个Node分配的IP范围保存到etcd中。
- 新建Pod时,flannel会从etcd中取出属于该Node的ip,分配给Pod,再在etcd中记录下这个Pod的IP。这样etcd中就会存有一张Node IP与Pod IP对应的“路由表”。
- 当Pod需要跨Node通信时,数据包经过Node中的路由会到flannel中,flannel通过etcd查询到目的Pod IP的Node IP,使用flannel的Backends对数据包进行分装,发送给目的Node处理。目的Node拿到数据包后解开封装,拿到原始数据包,再通过Node的路由送到相应的Pod。
- flannel的Backends有多种实现方式:VXLAN、UDP、gce…..具体参考官方文档。官方推荐的是VXLAN,之前介绍docker swarm时就提到过,swarm的overlay网络也是通过VXLAN实现的。关于vxlan的具体实现原理可以参考《vxlan 协议原理简介》。
flannel为Pod分配ip有不同的实现方式,Kubernetes推荐的是基于CNI,另一种是直接与docker结合,我觉得是在CNM的基础上做出的修改。
2.2 基于CNI(container network interface)
Container Network Interface (CNI) 最早是由CoreOS发起的容器网络规范,是Kubernetes网络插件的基础。其基本思想为:Container Runtime在创建容器时,先创建好network namespace,然后调用CNI插件为这个netns配置网络,其后再启动容器内的进程。现已加入CNCF,成为CNCF主推的网络模型。
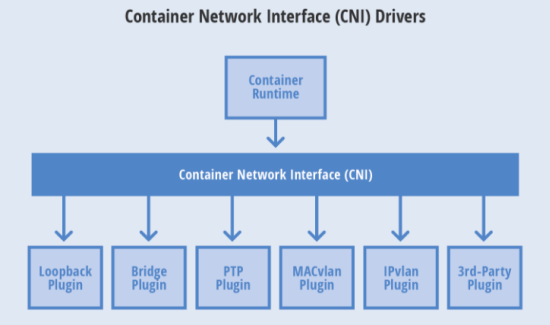
这个协议连接了两个组件:容器管理系统和网络插件。它们之间通过 JSON 格式的文件进行通信,实现容器的网络功能。具体的事情都是插件来实现的,包括:创建容器网络空间(network namespace)、把网络接口(interface)放到对应的网络空间、给网络接口分配 IP 等等。
使用CNI后,容器的IP分配就变成了如下步骤:
kubelet 先创建pause容器生成network namespace调用网络CNI driverCNI driver 根据配置调用具体的cni 插件cni 插件给pause 容器配置网络pod 中其他的容器都使用 pause 容器的网络
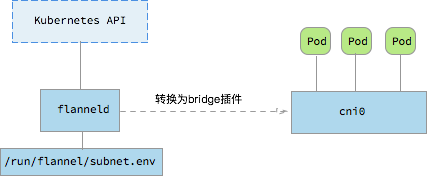
这时候Pod就直接以cni0作为了自己的网关,而不是docker默认的docker0。所以使用docker inspect查看某个pause容器时,是看不到它的网络信息的。kubeasz就是基于这种方式部署的flannel,关于如何部署可以看看安装flannel网络组件.md
2.3 基于docker CNM
这种方式需要把/run/flannel/subnet.env中的内容写到docker的环境变量配置文件/run/flannel/docker中,然后在docker engine启动时带上相应参数EnvironmentFile=-/run/flannel/docker。这样docker0的ip地址就会是flannel为该Node分配的地址了。
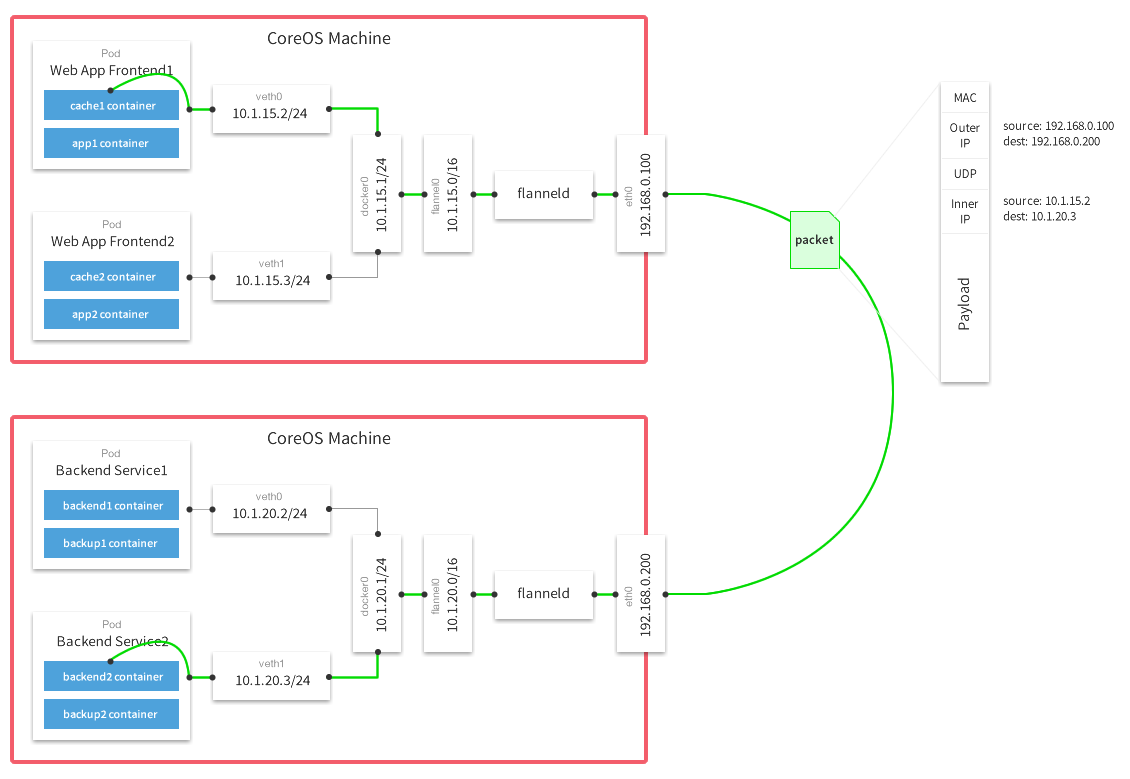 这样子Pod IP是docker engine分配的,Pod也是以docker0为网关,通过veth连接network namespace,符合CNM中的定义。
这样子Pod IP是docker engine分配的,Pod也是以docker0为网关,通过veth连接network namespace,符合CNM中的定义。
2.4 比较
相比起来,明显是Kubernetes推荐的CNI模式要好一些。
- CNI中,docker0的ip与Pod无关,Pod总是生成的时候才去动态的申请自己的IP,而CNM模式下,Pod的网段在docker engine启动时就已经决定。
- CNI只是一个网络接口规范,各种功能都由插件实现,flannel只是插件的一种,而且docker也只是容器载体的一种选择,Kubernetes还可以使用其他的,比如rtk…官方博客也对此做过说明:Why Kubernetes doesn’t use libnetwork
2.5 reference
Pod Network应该是Kubernetes中最主要也是最复杂的网络结构了,自己的理解还不够,再列一些参考的文章:
三 Service Network
我觉得Service IP只能算一种假IP,除了在iptables中有相应的规则链,并没有任何网络链路的底层实现。所以我觉得它更像是一种集群内的“域名”,通过kube-proxy设置的iptables规则进行“DNS”解析,最终访问到对应的Pod。具体可以看看上一篇中关于kube-proxy的内容。
3.1 外部访问Service
另外这个虚拟的Service IP(Cluster IP)只能在集群内部才能访问到,如果要从外部访问,可以用一下几种方式:
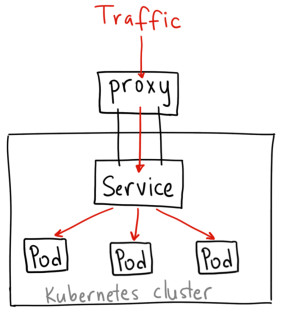
- Porxy API
这种是直接使用apiserver,通过Proxy API将访问请求转发到对应服务的ClusterIP上。比如访问grafana服务:http://localhost:8080/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy/
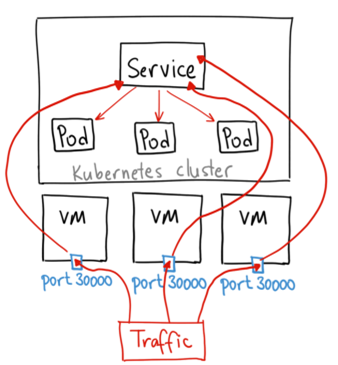
- NodePort
NodePort是把服务的端口映射到集群每一个Node上的某一个端口上,这样访问集群中任意一个Node的请求都可以被转发到对应的服务的ClusterIP上。
- LoadBalancer
LoadBalancer是使用云服务提供商的负载均衡器,将来自外网的访问请求转发到ClusterIP上。
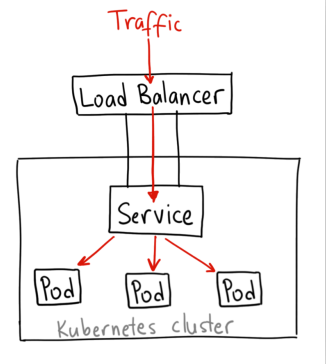
以上三中方式都是Service的type所支持的类型。但各有各的问题,ClusterIP通常只适合debug时访问,因为apiserver的权限过大。而NodePort是直接将集群的Node暴露在外,而且每一个服务就要占用一个端口,非常不便于管理。LoadBalancer一般都是服务提供商付费使用。
- Ingress
Ingress感觉就是一个nginx反代,依据不同的server_name将请求转发给不同的Service。只需要暴露一个入口,就可以访问到集群内很多的服务。Ingress并不是Service的一种,而是对集群内Service入口的统一管理。
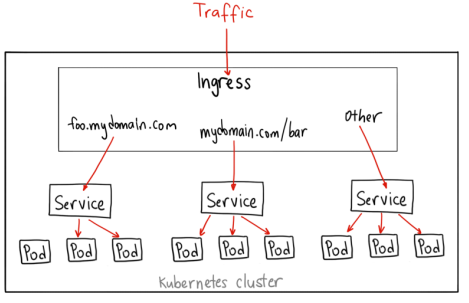
更详细的关于集群外访问服务的内容可以参考google cloud的介绍。
