由于云主机项目提供的是整套虚拟化服务,上层服务并没有直接用到物理节点上的CPU,而是通过创建云主机的时候,指定规格来申请vcpu资源来使用,虚拟化出vcpu,需要得到硬件的支持,通常来说就是Intel VT和AMD-V,在此基础上一个云主机实际上是通过一个QEMU用户进程而在节点机上运行的,而vcpu实际上就是以QEMU进程的线程而存在
来看云主机vcpu和节点cpu之间的关系
~$ sudo virsh vcpuinfo instance-000ac3af VCPU: 0 CPU: 26 State: running CPU time: 8600.1s CPU Affinity: ----yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy VCPU: 1 CPU: 13 State: running CPU time: 8064.1s CPU Affinity: ----yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy
通过virsh可以查看云主机vcpu对应节点机物理cpu的core id,比如这里可以看出来instance-000ac3af这台云主机申请了两个vcpu,vcpu0此刻运行在了物理cpu 26上,vcpu此刻运行在了物理cpu 13上,说此刻是因为它不停在变,在各个物理cpu上辗转,随系统调度,从CPU Affinity的结果也可以看出来,vcpu除了0-3这四个物理cpu,其它cpu都能够调度上去,这四个物理cpu其实是为节点上所有服务(OpenStack)所预留
直接宿主机上通过top也可以看到两个vcpu所在的线程以及调度的物理CPU
top - 15:33:54 up 66 days, 4:38, 2 users, load average: 11.61, 10.38, 10.11 Threads: 538 total, 0 running, 538 sleeping, 0 stopped, 0 zombie %Cpu(s): 20.7 us, 1.1 sy, 0.0 ni, 78.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st MiB Mem: 387143 total, 227153 used, 159990 free, 660 buffers MiB Swap: 0 total, 0 used, 0 free, 109773 cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND P 129806 root 20 0 10.4g 2.1g 14m S 4.3 0.5 144:26.00 CPU 0/KVM 42 129809 root 20 0 10.4g 2.1g 14m S 2.7 0.5 135:26.78 CPU 1/KVM 36
从上面的小例子可以理解,云主机的vcpu和宿主机的物理cpu并没有直接的对应关系,但如果所有云主机里cpu负载都很高,对整个宿主机来说总负载也会很高,这时候系统服务以及云主机中的业务都需要进行异常测试;同理,如果宿主机本身负载就比较高,那么云主机中的cpu就会相对繁忙
云主机vcpu和宿主机cpu之间没有严格的关系,但假如一个物理cpu只虚拟化出一个vcpu,那么宿主机(48CPU,预留4个)最多能虚拟化出44个vcpu,最终整个节点只能创建出vcpu为1这种规格的云主机44台,本身cpu的处理能力比较过剩,假如每个云主机负载还十分空闲,那么就会造成十分严重的资源浪费,或者说利用率太低,因此就有了cpu超售比例这个概念,作用是为了资源利用率的最大化
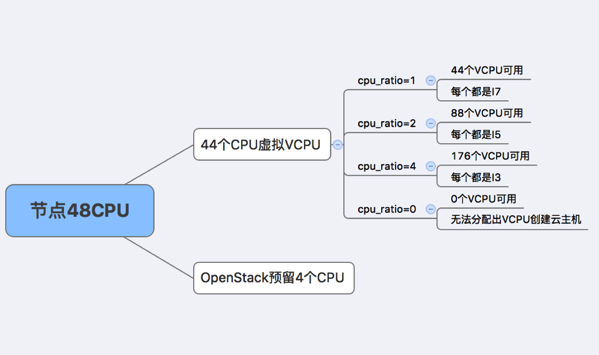
从上图可以很清楚地看出,超售比能够在基础可虚拟化的cpu数量的基础上提升vcpu的倍数,这样就能够创建更多的资源,但需要注意几点:
1) 宿主机物理cpu是固定的,所虚拟化出的vcpu越少,平均每个vcpu的处理能力越强,反之越弱,就好比如果超售比例为1,那么vcpu和物理cpu数量1:1,可以理解为每个vcpu的处理能力和每个物理cpu相当;如果超售比例设为2,那么vcpu和物理cpu数量2:1,此时vcpu的处理能力就只有物理cpu的一半,一个不恰当的比喻,超售比为1的时候,每个vcpu相当于I7的能力,超售比为2的时候,每个vcpu相当于I5的处理能力(假如I7处理能力为I5的两倍)
2) 宿主机上vcpu资源如果用尽,根据超售比每个vcpu的处理能力很好理解,平均即可,但假如未完全用尽,算法就有些不同了,比如cpu超售比例为2,一共可以虚拟化出88个vcpu,如果创建了88台vcpu为1规格的云主机,那么每个vcpu的处理能力就是44 * 物理CPU / 88 = 半个物理CPU的处理能力,但假如宿主机上创建了66台vcpu为1规格的云主机,每个vcpu的处理能力并不是半个物理CPU的处理能力,而是44 * 物理CPU / 66 = 2/3个物理CPU的处理能力,假如继续新建一个vcpu为1的云主机,每个vcpu的处理能力就是44 * 物理CPU / 67 个物理CPU的处理能力,也就是说每个vcpu的处理能力都不固定,而是随着vcpu数量的变化,每个vcpu的能力来做平衡,从线程的角度理解就是,多了一个耗费cpu负载的线程,平均每个线程的处理能力就会降低
3) 正常情况下,CPU的处理能力都是过剩的,假如超售比例为1,节点上44个拥有最大处理能力的vcpu全部都是空负载,如果每个内存512M一共就用了20G左右内存,而这些空负载的vcpu却使得节点上无法继续创建了,造成严重的资源浪费,此时如果超售比设为4,那44个空负载的云主机可以随便打发1/4的cpu处理能力,剩下3/4的cpu资源还可以充分利用起来
4) 从收益的角度,由于这些计算资源都要收费,在合理资源利用最大化的基础上,数量越多,费用收入也会更大
由于cpu的使用涉及到宿主机和云主机,以及超售状况,因此在测试过程中,要结合宿主机的cpu负载和云主机的cpu负载进行异常测试,要关注的是宿主机的load和软中断数量以及满cpu负载和空cpu负载的云主机的运行状态以及服务情况
cpu负载工具,这里主要介绍burnintest和stress
burnintest不开源,Linux环境下只提供32bit/64bit的可执行程序,版本也相对较老,但是可用
下载地址:wget http://www.passmark.com/ftp/burnintest_2.1.tar.gz
运行方式:./bit_cmd_line_x64(根据操作系统环境选择32位或者64位)
参数:
默认是15分钟一个cycle
指定参数-D 1:
Run for 1.0 minutes or 0 cycles (0 is forever)
指定参数-X 1:
Run for 15.0 minutes or 1 cycles (0 is forever)
最终压测结果可以直接通过top或者htop来查看
stress,压力测试工具
安装:sudo apt-get/yum install stress
运行方式:/usr/bin/stress –c N
其中,N代表产生N个进程来反复不停地计算随机数的平方根,会加满N个CPU负载
